Simple Linear Regression
Simple linear regression (SLR) is a statistical tool used to examine the relationship between one predictor (independent) variable and a single quantitative response (dependent) variable. Simple linear regression analysis produces a regression equation that can be used for prediction. A typical experiment involves observing a sample of paired observations in which the independent variable (X) may have been fixed at a variety of values of interest and the dependent variable has been observed. These observations are used to create an equation that can be used to predict the dependent variable given a value of the independent variable.
Appropriate Applications for Regression Analysis
Design Considerations for Regression Analysis
There Is a Theoretical Regression Line
The regression line calculated from the data is a sample-based version of a theoretical line
describing the relationship between the independent variable (X) and the dependent
variable (Y). The theoretical line has the form
Y = α + βX+ ε
where α is the y-intercept, β is the slope, and ε is an error term with zero mean and
constant variance. Notice that β = 0 indicates that there is no linear relationship between X
and Y.
The Observed Regression Equation Is Calculated From the Data Based on the Least Squares Principle
The regression line that is obtained for predicting the dependent variable (Y) from the
independent variable (X) is given by
Ŷ = a + bX,
and it is the line for which the sum-of-squared vertical differences from the points in the
X-Y scatterplot to the line is a minimum. In practice, Ŷ is the prediction of the dependent
variable given that the independent variable takes on the value X. We say that the values a
and b are the least squares estimates of α and β, respectively. That is, the least squares
estimates are those for which the sum-of-squared differences between the observed Y
values and the predicted Y values are minimized. To be more specific, the least squares
estimates are the values of a and b for which the sum of the quantities (Yi – a – bXi
)
2
, i =
1, … , N is minimized.
Several Assumptions Are Involved
These include the following:
1. Normality. The population of Y values for each X is normally distributed.
2. Equal variances. The populations in Assumption 1 all have the same variance.
3. Independence. The dependent variables used in the computation of the regression
equation are independent. This typically means that each observed X-Y pair of
observations must be from a separate subject or entity.
You will often see the assumptions above stated in terms of the error term ε Simple linear
regression is robust to moderate departures from these assumptions, but you should be
aware of them and should examine your data to understand the nature of your data and
how well these assumptions are met.
Hypotheses for a Simple Linear Regression Analysis
To evaluate how well a set of data fits a simple linear regression model, a statistical test is
performed regarding the slope (α) of the theoretical regression line. The hypotheses are as
follows:
H0
: β = 0 (the slope is zero; there is no linear relationship between the variables).
Ha
: β ≠ 0 (the slope is not zero; there is a linear relationship between the variables).
The null hypothesis indicates that there is no linear relationship between the two variables.
One-sided tests (specifying that the slope is positive or negative) can also be performed. A
low p-value for this test (less than 0.05) would lead you to conclude that there is a linear
relationship between the two variables and that knowledge of X would be useful in the
prediction of Y.
Hypothetical Example
Click Here To Download Sample Dataset (SPSS Format)
Research Scenario and Test Selection
The scenario used to explain the SPSS regression function centers on a
continuation of the pool example presented in the introduction. You will
enter hypothetical data for the “number of patrons” (dependent variable)
at a public swimming pool and that “day’s temperature” (independent variable). The research will investigate the relationship between a day’s temperature and the number of patrons at the public swimming pool. The
researcher also wishes to develop a way to estimate the number of patrons
based on a day’s temperature. It appears that the single linear regression
method might be appropriate, but there are data requirements that must
be met.
One data requirement (assumption) that must be met before using linear regression is that the distributions for the two variables must approximate the normal curve. There must also be a linear relationship between
the variables. Also, the variances of the dependent variable must be equal
for each level of the independent variable. This equality of variances is
called homoscedasticity and is illustrated by a scatterplot that uses standardized residuals (error terms) and standardized prediction values. And
yes, we must assume that the sample was random.
Research Question
The current research investigates the relationship between a day’s temperature and the number of patrons at the swimming pool. We are interested in determining the strength and direction of any identified
relationship between the two variables of “temperature” and “number of
patrons.” If possible, we wish to develop a reliable prediction equation
that can estimate the number of patrons on a day having a temperature
that was not directly observed. We also wish to generalize to other days
having the same temperature and to specify the number of expected
patrons on those days.
The researcher wishes to better understand the influence that daily
temperature may have on the number of public pool patrons. The
alternative hypothesis is that the daily temperature directly influences
the number of patrons at the public pool. The null hypothesis is the
opposite: The temperature has no significant influence on the number
of pool patrons.
Sample Output
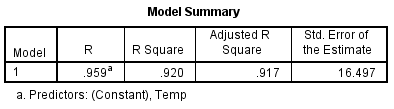
Interpretation:
R is the correlation coefficient between the two variables; in this case, the correlation between “temperature” and “number of patrons” is high at .959. The next column, R Square, indicates the amount of change in the dependent variable (“number of patrons”) that can be attributed to our one independent variable (“temperature”). The R Square value of .920 indicates that 92% (100 × .920) of the variance in the number of patrons can be explained by the day’s temperature. We now begin to conclude that we have a “good” predictor for number of expected patrons when consideration is given to the day’s temperature. Next, we will examine the ANOVA table.
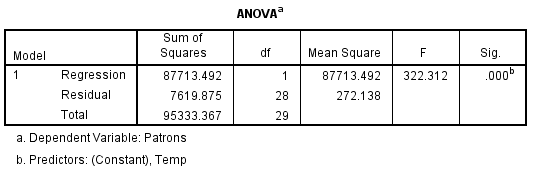
The ANOVA table presented here indicates that the model can accurately explain variation in the dependent variable. We are able to say this since the significance value of .000 informs us that the probability is very low that the variation explained by the model is due to chance. The conclusion is that changes in the dependent variable resulted from changes in the independent variable. In this example, changes in daily temperature resulted in significant changes in the number of pool patrons.
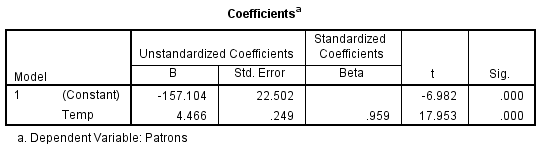
The Coefficients table presented in here is most important when
writing and using the prediction equation. Please don’t glaze over it; but
we must present some basic statistics before you can use SPSS to do the
tedious work involved in making predictions. The prediction equation takes
the following form:
Ŷ = a + bX,
where Ŷ is the predicted value, a the intercept, b the slope, and x the
independent variable.
Let’s quickly define a couple of terms in the prediction equation that
you may not be familiar with. The slope (b) records the amount of change
in the dependent variable (“number of patrons”) when the independent
variable (“day’s temperature”) increases by one unit. The intercept (a) is the
value of the dependent variable when x = 0.
In simple words, the prediction equation states that you multiply the
slope (b) by the values (x) of the independent variable (“temperature”) and then add the result of the multiplication (bx) to the intercept (a)—
not too difficult. But where (in all our regression output) do you find the
values for the intercept and the slope? Table here provides the answers.
(Constant) is the intercept (a), and Temperature is the slope (b). The
x values are already recorded in the database as temp—you now have
everything required to solve the equation and make predictions.
Substituting the regression coefficients, the slope and the intercept, into
the equation, we find the following:
Ŷ = -157.104 + (4.466x).
The x value represents any day’s temperature that might be of interest and
each of those temperatures recorded during our prior data collection.
Let’s put SPSS to work and use our new prediction equation to make
predictions for all the observed temperature values. By looking at the
observed numbers of patrons and the predicted number of patrons, we can
see how well the equation performs.